
Listing & counting stitches

Contents
Introduction
A stitch is made by crossing and twisting two pairs of bobbins. With “twist” we mean: twist both pairs, twist right pair, or twist left pair. We can abbreviate this with “C” (cross), “T” (twist both pairs), “R” (twist right pair) and “L” (twist left pair). For listing and counting stitches we consider only stitches that start and end with a cross. Twists before the first cross and after the last are viewed as actions between stitches.
Please note: CT is represented in our list as C with a twist on both pairs between stitches. Similarly, CTC and CTCT are both represented as CTC in our list, where CTCT has a twist on each pair between stitches and CTC does not.
A stitch can be described by a word formed from the symbols “C”, “L”, “R”, “T”. These words have to obey certain rules. These rules come from observing examples of real lace, and from some limits we set ourselves in this document.
To help us count and catalogue the words representing stitches, the symbols are ordered: “C” before “T”, “T” before “R”, “R” before “L”.
Please note: the following rules are to be applied for counting and cataloguing only.
Results
A complete list of stitch words of the specified length can be downloaded as a .txt file by clicking on “results” in the corresponding row of the table below.
The first row of the file shows counts for the number of words. The words are grouped by their symmetry: first the words that are completely symmetric (“b=p=q=d”), then the words that are left-right-symmetric (“b=d”), etc.
Words with two consequtive C’s are written in lower case.
Please note: only one orientation of each word is listed. See how to make mirrored words to create the other orientations.
Please note: the following list consists of words starting and ending with “C”. In practice, any number of twists can be applied to the left pair or right pair travelling between two stitches.
| word length | count | subset without "CC" | symmetric words (b=d=p=q) | results | download results |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | C, however, a ground with only "C" will fall apart | results |
| 2 | 1 | 0 | 1 | cc, however, a ground with only "cc" will fall apart | results |
| 3 | 2 | 2 | 1 | CTC; CRC; | results |
| 4 | 5 | 3 | 1 | cctc; ccrc; CTTC; CTRC; CRRC; | results |
| 5 | 13 | 8 | 3 | cctcc; ccrcc; ccttc; cctrc; ccrrc; CTCTC; CTCRC; CRCRC; CRCLC; CTTTC; CTTRC; CTRRC; CRRRC | results |
| 6 | 24 | 8 | 2 | cctctc; cctcrc; ccrctc; ccrcrc; ccrclc; ccttcc; cctrcc; ccrrcc; cctttc; ccttrc; cctrrc; ccrrrc; ctcctc; ctccrc; crccrc; crcclc; CTCTTC; CTCTRC; CTCRRC; CRCRRC; CRCLLC; CTTCRC; CTRCRC; CTRCLC | results |
| 7 | 67 | 30 | 4 | results | |
| 8 | 168 | 57 | 3 | results | |
| 9 | 460 | 157 | 7 | results | |
| 10 | 1220 | 334 | 6 | results | |
| 11 | 3389 | 874 | 13 | results | |
| 12 | 9245 | 2040 | 10 | results | |
| 13 | 25677 | 12498 | 22 | results |
Twists between stitches
Between every two stitches, zero, one or more twists can be made. Examples:
- CRC : CRCT, CRCR, CRCL, CRCTT, CRCTR, CRCTL, CRCRR, CRCLL, CRCTTT, CRCTTR, CRCTRR, CRCRRR, …
- CTCTC : CTCTCT, CTCTCR, CTCTCTT, CTCTCTR, CTCTCRR, CTCTCTTT, CTCTCTTR, CTCTCTRR, CTCTCRRR, …
Method used
Observations from real lace
- Twists before the first cross or after the last cross are viewed as actions that occur between stitches and can be done either before the stitch or after the stitch.
- Cross only is a valid stitch. However, a lacework with only crosses and no twists at all does not hold together. Cross only can only be used in combination with other stitches.
- Twist left followed by twist right is the same as twist right followed by twist left. This is also the same as twisting both pairs, i.e.: LR = RL = T.
- Twisting both left and right pairs is treated as one action because the left and right sides are done in parallel by the lacemaker.
- Different placing of pins can change the appearance of the ground. Pins are not considered in our lists and counting.
Rules for counting and cataloguing words representing stitches
- Every word must start with a C.
- Every word must end with a C.
- Every word of length greater than two must contain at least one symbol of the set { T, R, L }.
- For a consecutive sequence of the symbols { T, R, L } in a word, if the sequence contains an R, it cannot contain an L. Similarly, if the sequence contains an L, it cannot contain an R.
- For a consecutive sequence of the symbols { T, R, L }, the sequence must be arranged in least lexicographical order: T < R < L. (This gives a canonical form. Lexicographical order, which is like alphabetical order, puts all of the symbols in a consistent order so that strings like RTRR, RRTR, TRRR and RRTR, when sorted, are all the same, i.e. TRRR.)
- A word (represented by b) and its mirrored versions (d, p and q) are treated as equivalent and only counted once. The canonical form of the word is the lexicographically least variant of its b, d, p and q forms. For example, the words ccrclc, cclcrc, crclcc, and clcrcc are all related by mirror reflections so they count as one unique word which is represented in our list by the canonical form ccrclc. Consequence: in the canonical form, the first occurrence of a symbol from { R, L } must be an “R”.
Limitations
- We consider words up to a maximal length of 13 symbols.
- The number of consecutive symbols from { C } in a word is limited to two.
- The number of consecutive symbols from { T, R, L } in a word is limited to three.
How to make mirrored words
Please note: the drawings of stitches in this section are drawn on a diagonal net.
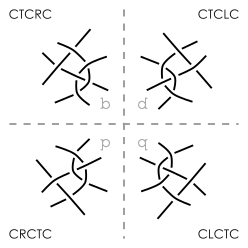
Mirrored representation: b ⇔ d, p ⇔ q
a. Replace all R in the word with L and all L with R
CTCRC ⇒ CTCLC
Mirrored representation: b ⇔ p, d ⇔ q
a. Read word backwards
b. Re-order twist groups: T < R < L
CTCRC ⇒ CRCTC
CTRCTLC ⇒ CLTCRTC ⇒ CTLCTRC
How to make the quartet of words
a. Apply mirror b ⇒ d
b. Apply mirror d ⇒ q
c. Apply mirror q ⇒ p
CTCRC ⇒ CTCLC ⇒ CLCTC ⇒ CRCTC
CTRCLC ⇒ CTLCRC ⇒ CLCTRC ⇒ CRCTLC
Internal symmetry
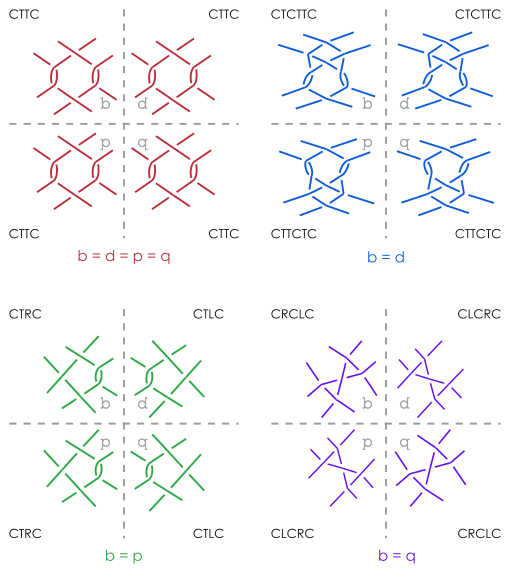
The mirrored representations of word b and d are identical if b has no left or right twist actions (only T, no R and no L). b=d in the picture above.
The mirrored representations of word b and p are identical if b is a palindrome. b=p in the picture above.
All mirrored representations d, q and p of word b are identical if b has no left or right twist and is a palindrome. b=d=p=q in the picture above.
Listing and counting
In this section we describe how we have listed and counted the words.
We have chosen to list and count the words based on the length of the word, which also corresponds to the number of actions performed by the lacemaker.
As examples we use words of length 6 (but not the complete set).
Notations and short notations
Let 𝓐 = { a, b, c }; and 𝓑 = { p, q, r }
- 𝓐 ⊗ 𝓑 = { a, b, c } ⊗ { p, q, r }. This means: make all combinations using all the symbols in the first set and combine them with all the symbols in the second set. This gives a new set: { ap, aq, ar, bp, bq, br, cp, cq, cr }. A word is one of these combinations. Please note: do not change the order. In this example, “ra” is not a valid word.
- Short notation: 𝓐𝓑 means 𝓐 ⊗ 𝓑 and p𝓐 means { p } ⊗ 𝓐 = { pa, pb, pc }.
Defining sets
n : the length of the words we are counting
𝓒all = { c, cc }
𝓣1 = { t, r, l }
𝓣2 = { tt, tr, tl, rr, ll }
𝓣3 = { ttt, ttr, ttl, trr, tll, rrr, lll }
Please note: 𝓣3 = t𝓣2 ∪ { rrr, lll }
𝓣all = 𝓣1 ∪ 𝓣2 ∪ 𝓣3
To apply rule 6, we add extra base sets that do not include l’s or series of only t’s.
𝓑1 = { r }
𝓑2 = { tr, rr }
𝓑3 = { ttr, trr, rrr }
Word forming
A word is a formed by choosing symbols alternately from 𝓒all and 𝓣all, ending with a symbol from 𝓒all. Valid words before applying rule 6 are elements from sets like:
𝓒all ⊗ 𝓣all ⊗ 𝓒all
𝓒all ⊗ 𝓣all ⊗ 𝓒all ⊗ 𝓣all ⊗ 𝓒all
For the examples we use n = 6.
Step 1: Make basic set with proto-words
a. List all number 1, 2, …, 2(n-2)
1, 2, …, 16
b. Replace all numbers with their binary representation, length (n - 2)
0001, 0010, …, 1111
c. Place “0” on front and back of each word
000010, 000100, …, 011110
d. Replace all “0” with “c”, all “1” with “𝓣1”
cccc𝓣1c, ccc𝓣1cc, …, c𝓣1𝓣1𝓣1𝓣1c
e. Remove all words with more than two consecutive “c”. Remove all words with more than three consecutive “𝓣1”
…, cc𝓣1𝓣1𝓣1c, c𝓣1cc𝓣1c, c𝓣1c𝓣1𝓣1c, c𝓣1𝓣1c𝓣1c, …
Step 2: Avoid words b where b = d
For examples we use the following proto-words: cc𝓣1𝓣1𝓣1c, c𝓣1cc𝓣1c, c𝓣1c𝓣1𝓣1c, c𝓣1𝓣1c𝓣1c
a. First make words with all “t”
b. Replace 𝓣1 with 𝓓i in proto-word set (to be specified later)
cctttc, cc𝓓3c
ctcctc, c𝓓1cc𝓓1c
ctcttc, c𝓓1c𝓓2c
cttctc, c𝓓2c𝓓1c
c. Only one of the 𝓓-sets in the proto-word is the set with the first “r” in the word. Call this set “𝓑”, leading to more proto-words
cctttc, cc𝓑3c
ctcctc, c𝓑1cc𝓓1c, c𝓓1cc𝓑1c
ctcttc, c𝓑1c𝓓2c, c𝓓1c𝓑2c
cttctc, c𝓑2c𝓓1c, c𝓓2c𝓑1c
d. All 𝓓 before a 𝓑 must be all t’s. Replace with t
e. No limits for 𝓓 after 𝓑. Replace with 𝓣i.
cctttc, cc𝓑3c
ctcctc, c𝓑1cc𝓣1c, ctcc𝓑1c
ctcttc, c𝓑1c𝓣2c, ctc𝓑2c
cttctc, c𝓑2c𝓣1c, cttc𝓑1c
f. Solve 𝓣 and 𝓑, giving the words we are looking for
cctttc, ccttrc, cctrrc, ccrrrc
ctcctc, crcctc, crccrc, crcclc, ctccrc
ctcttc, crcttc, crctrc, crctlc, crcrrc, crcllc, ctctrc, ctcrrc
cttctc, ctrctc, ctrcrc, ctrclc, crrctc, crrcrc, crrclc, cttcrc
g. If a word contains “cc”, write in lowercase. If a word does not contain “cc”, write in captitals.
cctttc, ccttrc, cctrrc, ccrrrc
ctcctc, crcctc, crccrc, crcclc, ctccrc
CTCTTC, CRCTTC, CRCTRC, CRCTLC, CRCRRC, CRCLLC, CTCTRC, CTCRRC
CTTCTC, CTRCTC, CTRCRC, CTRCLC, CRRCTC, CRRCRC, CRRCLC, CTTCRC
Step 3: Finding words b where b = p
a. For each word b found in step 2, make a quartet of words (see above)
b = CRCTLC, p = CTLCRC, d = CLCTRC, q = CTRCLC
b. Keep the lexicographycally lowest word
b = CRCTLC, p = CTLCRC, d = CLCTRC, q = CTRCLC. Word CTRCLC (q) is the lowest, and is kept.
Step 4: check for doubles
Typically, the doubles are the words where p (quartet 1) = b (quartet 2) or q (quartet 1) = b (quartet 2).
⇑